Chapter 5 - Data visualization essentials
Contents
Chapter 5 - Data visualization essentials#
2022 August 26

# import libraries
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# make sure plots show in the notebook
%matplotlib inline
After importing data, you should examine it closely.
Look at the raw data and perform rough checks of your assumptions
Compute summary statistics
Produce visualizations to illustrate obvious - or not so obvious - trends in the data
First, a note about matplotlib#
There are many different ways to visualize data in Python but they virtually all rely on matplotlib. You should take some time to read through the tutorial: https://matplotlib.org/stable/tutorials/introductory/pyplot.html.
Because many other libraries depend on matplotlib under the hood, you should familiarize yourself with the basics. For example:
import matplotlib.pyplot as plt
x = [1,2,3,4,5]
y = [2,4,6,8,20]
plt.scatter(x, y)
plt.title('title')
plt.ylabel('some numbers')
plt.xlabel('x-axis label')
plt.show()
Visualization best practices#
Consult Wilke’s Fundamentals of Data Visualization https://clauswilke.com/dataviz/ for discussions of theory and best practices.
The goal of data visualization is to accurately communicate something about the data. This could be an amount, a distribution, relationship, predictions, or the results of sorted data.
Utilize characteristics of different data types to manipulate the aesthetics of plot axes and coordinate systems, color scales and gradients, and formatting and arrangements to impress your audience!


Plotting with seaborn#
Basic plots#
Histogram: visualize distribution of one (or more) continuous (i.e., integer or float) variable.
Boxplot: visualize the distribution of one (or more) continuous variable.
Scatterplot: visualize the relationship between two continuous variables.
Study the seaborn tutorial for more examples and formatting options: https://seaborn.pydata.org/tutorial/function_overview.html
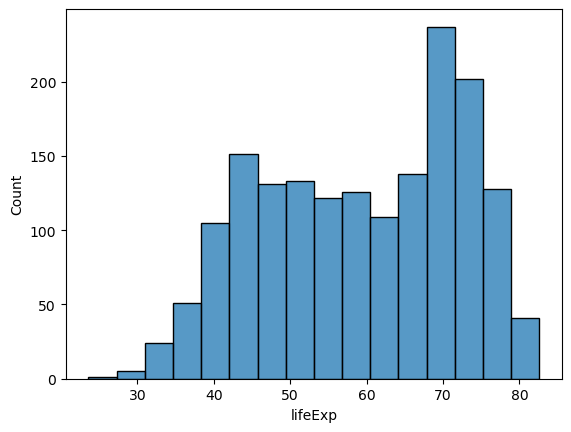
Histogram#
Use a histogram to plot the distribution of one continuous (i.e., integer or float) variable.
# load gapminder dataset
# !wget -P data/ https://raw.githubusercontent.com/EastBayEv/SSDS-TAML/main/fall2022/data/gapminder-FiveYearData.csv
gap = pd.read_csv("data/gapminder-FiveYearData.csv")
gap.head()
| country | year | pop | continent | lifeExp | gdpPercap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | 1952 | 8425333.0 | Asia | 28.801 | 779.445314 |
| 1 | Afghanistan | 1957 | 9240934.0 | Asia | 30.332 | 820.853030 |
| 2 | Afghanistan | 1962 | 10267083.0 | Asia | 31.997 | 853.100710 |
| 3 | Afghanistan | 1967 | 11537966.0 | Asia | 34.020 | 836.197138 |
| 4 | Afghanistan | 1972 | 13079460.0 | Asia | 36.088 | 739.981106 |
# all data
sns.histplot(data = gap,
x = 'lifeExp');
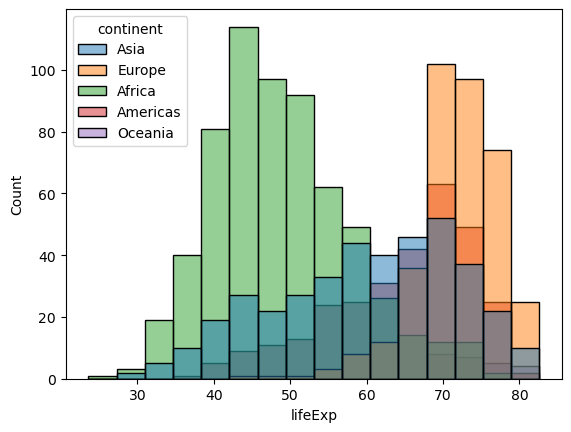
# by continent
sns.histplot(data = gap,
x = 'lifeExp',
hue = 'continent');
Boxplot#
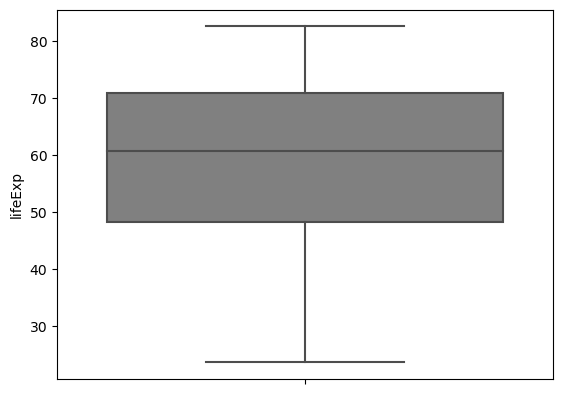
Boxplots can be used to visualize one distribution as well, and illustrate different aspects of the table of summary statistics.
# summary statistics
gap.describe()
| year | pop | lifeExp | gdpPercap | |
|---|---|---|---|---|
| count | 1704.00000 | 1.704000e+03 | 1704.000000 | 1704.000000 |
| mean | 1979.50000 | 2.960121e+07 | 59.474439 | 7215.327081 |
| std | 17.26533 | 1.061579e+08 | 12.917107 | 9857.454543 |
| min | 1952.00000 | 6.001100e+04 | 23.599000 | 241.165876 |
| 25% | 1965.75000 | 2.793664e+06 | 48.198000 | 1202.060309 |
| 50% | 1979.50000 | 7.023596e+06 | 60.712500 | 3531.846988 |
| 75% | 1993.25000 | 1.958522e+07 | 70.845500 | 9325.462346 |
| max | 2007.00000 | 1.318683e+09 | 82.603000 | 113523.132900 |
# all data
sns.boxplot(data = gap,
y = 'lifeExp',
color = 'gray');
gap.groupby('continent').count()['country']
continent
Africa 624
Americas 300
Asia 396
Europe 360
Oceania 24
Name: country, dtype: int64
# Sums to the total number of observations in the dataset
sum(gap.groupby('continent').count()['country'])
1704
# by continent
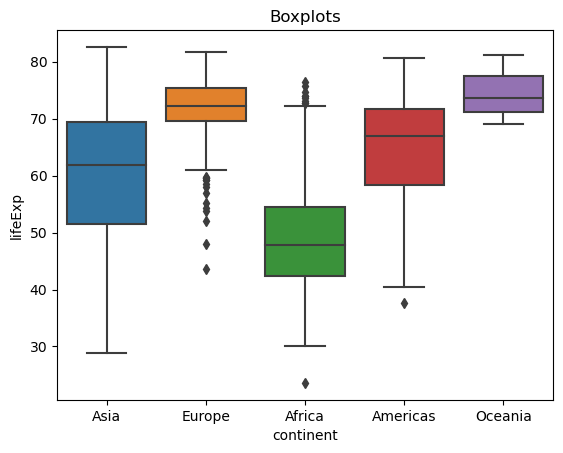
sns.boxplot(data = gap,
x = 'continent',
y = 'lifeExp').set_title('Boxplots');
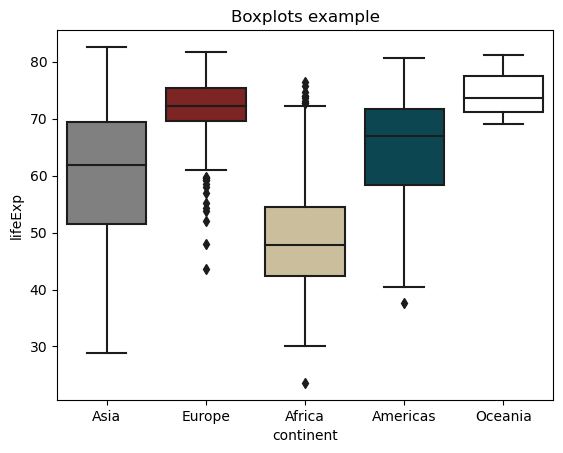
# custom colors
sns.boxplot(data = gap,
x = 'continent',
y = 'lifeExp',
palette = ['gray', '#8C1515', '#D2C295', '#00505C', 'white']).set_title('Boxplots example');
Scatterplot#
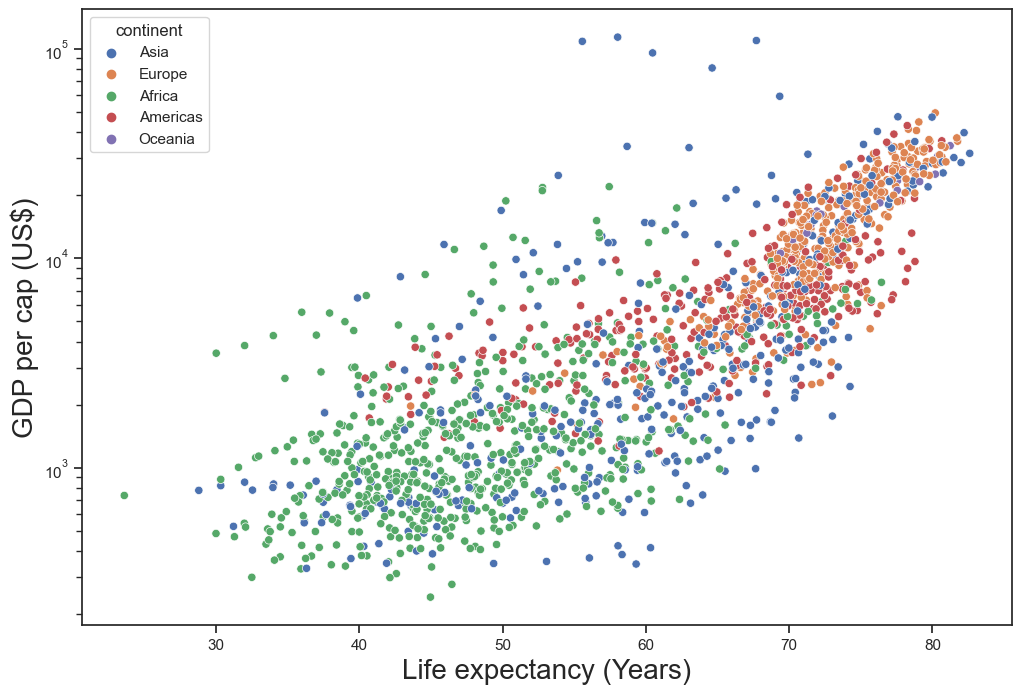
Scatterplots are useful to illustrate the relationship between two continuous variables. Below are several options for you to try.
### change figure size
sns.set(rc = {'figure.figsize':(12,8)})
### change background
sns.set_style("ticks")
# commented code
ex1 = sns.scatterplot(
# dataset
data = gap,
# x-axis variable to plot
x = 'lifeExp',
# y-axis variable to plot
y = 'gdpPercap',
# color points by categorical variable
hue = 'continent',
# point transparency
alpha = 1)
### log scale y-axis
ex1.set(yscale="log")
### set axis labels
ex1.set_xlabel("Life expectancy (Years)", fontsize = 20)
ex1.set_ylabel("GDP per cap (US$)", fontsize = 20);
### unhashtag to save
### NOTE: this might only work on local Python installation and not JupyterLab - try it!
# plt.savefig('img/scatter_gap.pdf')
Exercises - Penguins dataset#
Learn more about the biological and spatial characteristics of penguins!
Use seaborn to make a scatterplot of two continuous variables. Color each point by species.
Make the same scatterplot as #1 above. This time, color each point by sex.
Make the same scatterplot as #1 above again. This time color each point by island.
Use the
sns.FacetGridmethod to make faceted plots to examine “flipper_length_mm” on the x-axis, and “body_mass_g” on the y-axis.

Visualizations as an inferential tool#
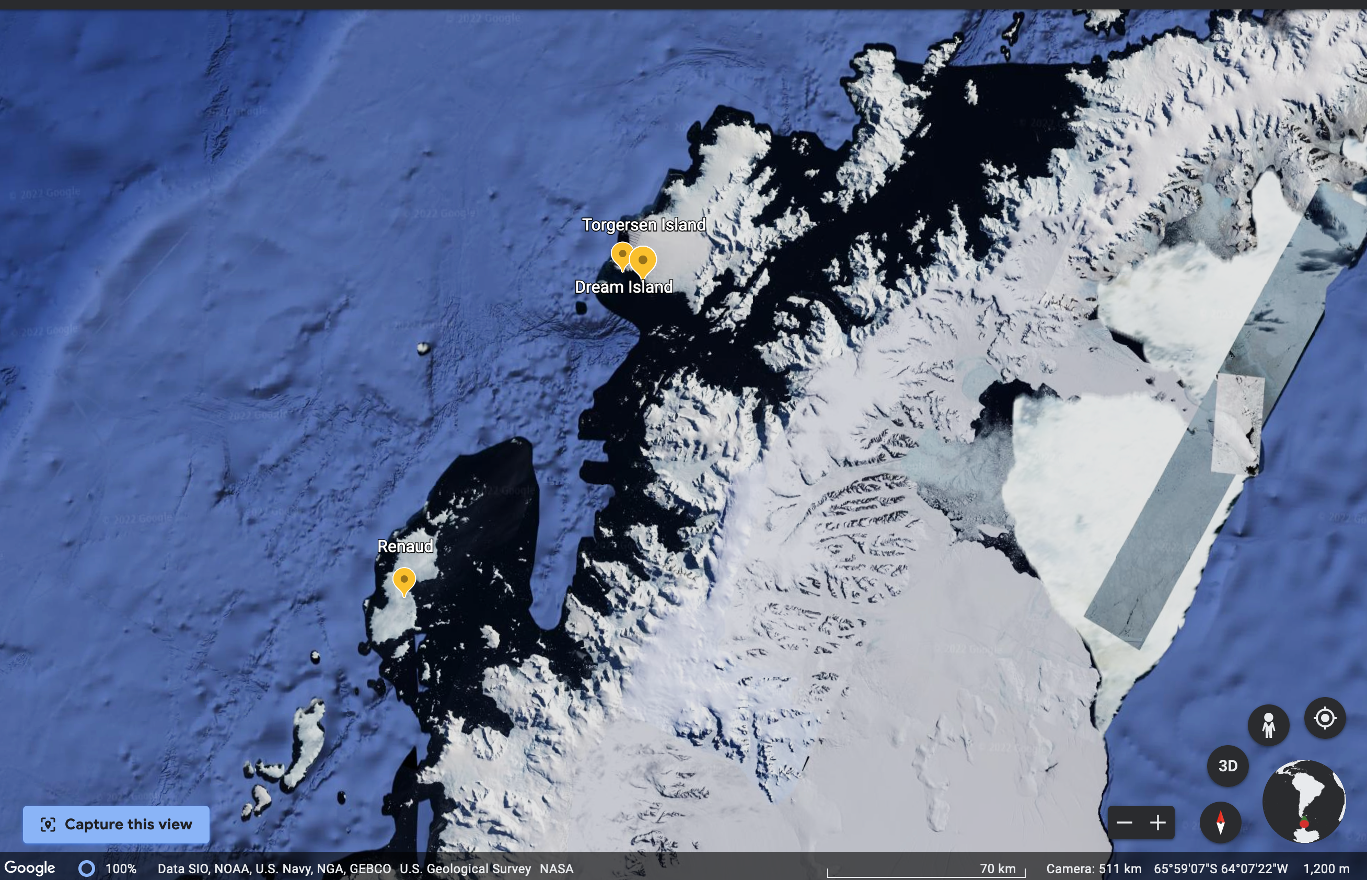
Below is a map of Antarctica past the southernmost tip of the South American continent.
The distance from the Biscoe Islands (Renaud) to the Torgersen and Dream Islands is about 140 km.
Might you suggest any similarities or differences between the penguins from these three locations?
Exercises - Gapminder dataset#
Figure out how to make a line plot that shows gdpPercap through time.
Figure out how to make a second line plot that shows lifeExp through time.
How can you plot gdpPercap with a different colored line for each continent?
Plot lifeExp with a different colored line for each continent.
What does this all mean for machine learning and text data?#
You might be wondering what this all means for machine learning and text data! Oftentimes we are concerned sorting data, predicting something, the amounts of words (and their synonyms) being used, or with calculating scores between words. As you will see in the next chapters, we do not change text to numbers, but we do change the representation of text to numbers. Read Chapter 6 “Core machine learning concepts; building text vocabularies” and Chapter 7 “English text preprocessing basics” to learn more!